Mixture of Experts for Dummies
This post is meant as a tutorial to help one get started with the basic concept of a Mixture-of-Expert. It looks at various types of MoEs and their individual nuances. Read on to get into the mix!
In the beginning…
Large Language Models (LLMs) are powerful neural networks that have achieved remarkable results in various natural language processing tasks. However, their massive size and computational complexity pose challenges for training and deployment. To address some of these challenges, Mixture of Experts (MoE) architecture has emerged as a promising technique.
MoE, MoE?
MoE or Mixture of Experts is a neural network architecture that divides a large model into smaller, specialized sub-models called experts. Each expert is trained to handle specific subtasks or input types. During inference, a gating network decides which expert(s) are best suited for each input, and only those experts are activated. This allows for more efficient computation and resource allocation compared to a single large model.
How does a MoE work?
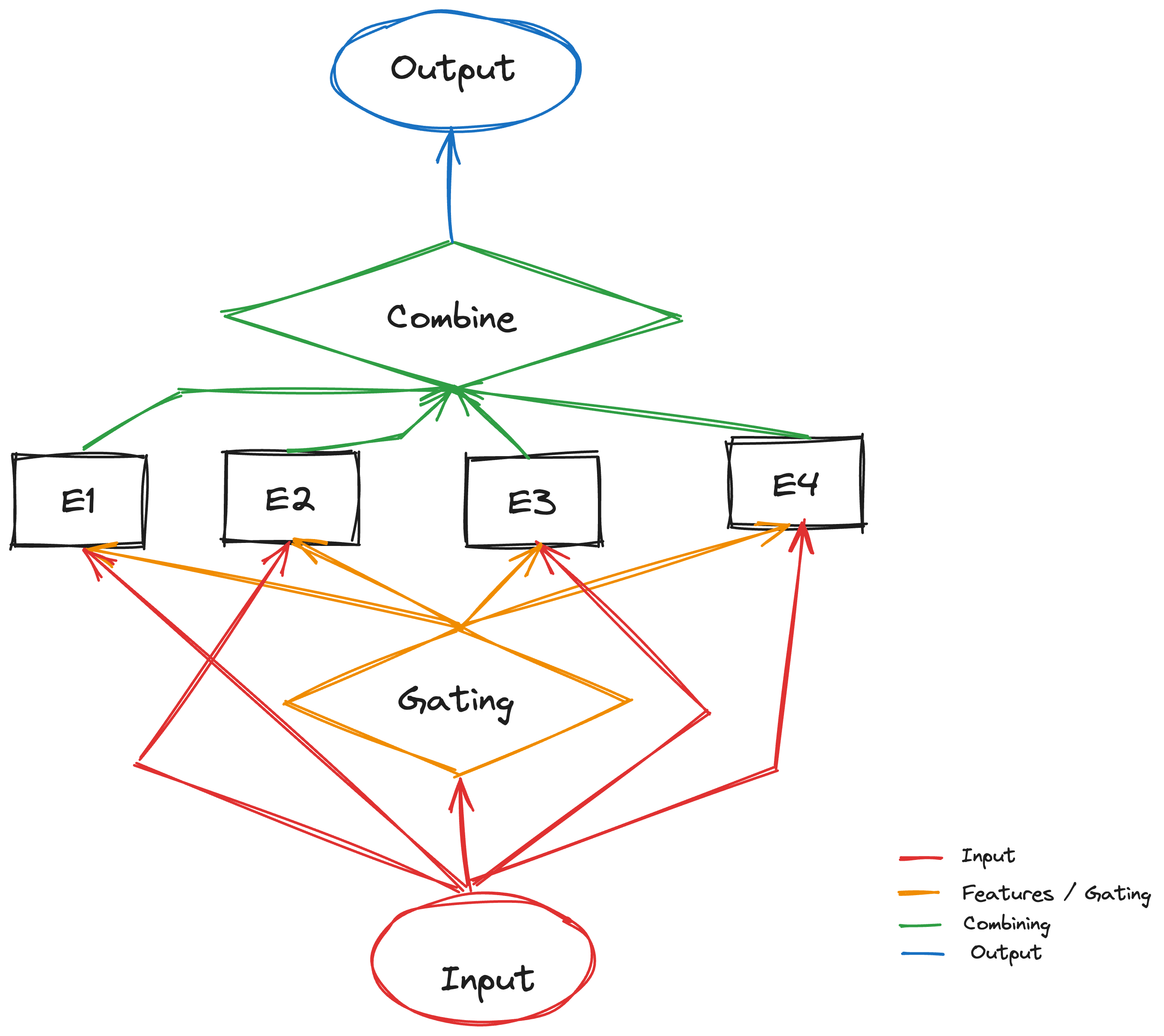
MoE consists of three main components:
- Expert networks: These are smaller sub-models trained on specific subtasks or input types.
- Gating network: This network determines which expert(s) are best suited for each input. It considers features of the input and the capabilities of each expert.
- Combiner: This component aggregates the outputs from the activated experts to produce the final output of the model.
Here’s a simplified breakdown of the MoE process:
- Input: The LLM receives an input (e.g., text, code, etc.).
- Feature extraction: Features are extracted from the input.
- Gating network: The gating network analyzes the features and activates a small subset of experts.
- Expert processing: Each activated expert processes the input and generates its own output.
- Combining: The outputs from the activated experts are combined to produce the final output of the LLM.
- \[\text{Output} = \sum_{i=1}^N \text{Expert}_i(\text{Input}) \cdot \text{Gating}(i)\]
Vanilla MoE
A Vanilla MoE is the simplest form of the architecture; it is a simple MoE with all the Experts switched on. We can get a brief idea from the image shown here:
Sparse MoE:
Imagine a team of experts working on a complex problem. Each expert has unique knowledge and skills, but it’s not efficient to involve all of them for every task.
Sparse MoE (Mixture of Experts): Google Brain proposed a solution: a network with many “experts,” but only a few are active for each task. This allows for a larger model capacity while saving resources.
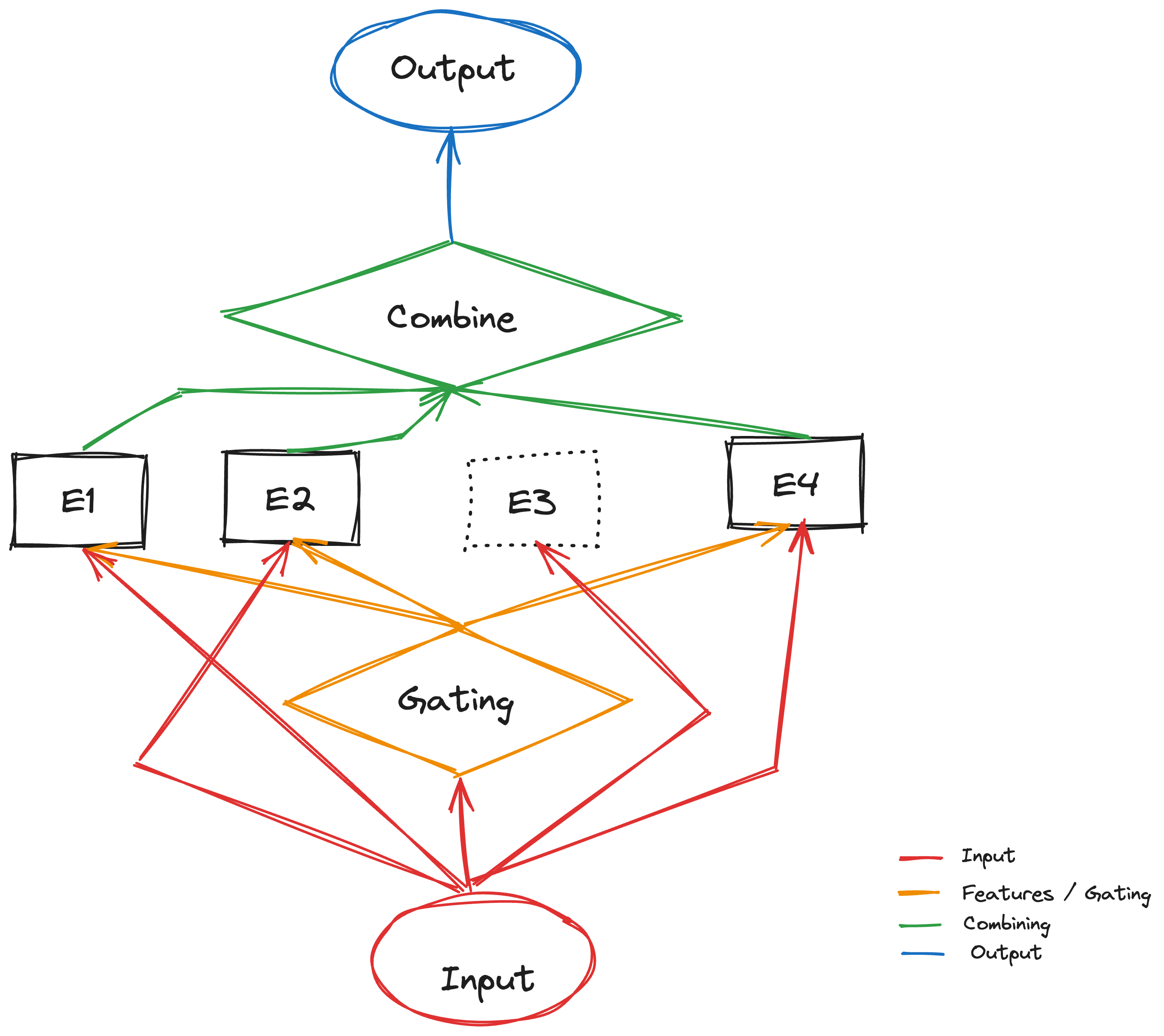
Goal: Achieve “single sample single expert processing.” This means the model chooses one specific expert for each input during inference, saving computation. Example: Imagine a team of 100 experts. The model only activates 3 experts for a specific task, significantly reducing computational cost.
During training, the model tends to favor “earlier” experts, making them more likely to be chosen. This leads to only a few experts being used effectively. This is called the “Expert Balancing problem.”
When models reached hundreds of billions of parameters, scaling became difficult. MoE (Mixture of Experts) resurfaced as an economical and practical solution. Google’s GShard pioneered MoE integration with Transformers. Subsequent work like Switch Transformer and GLaM further improved the technique. MoE reduced LLM parameters from billions to trillions. GLaM’s architecture:
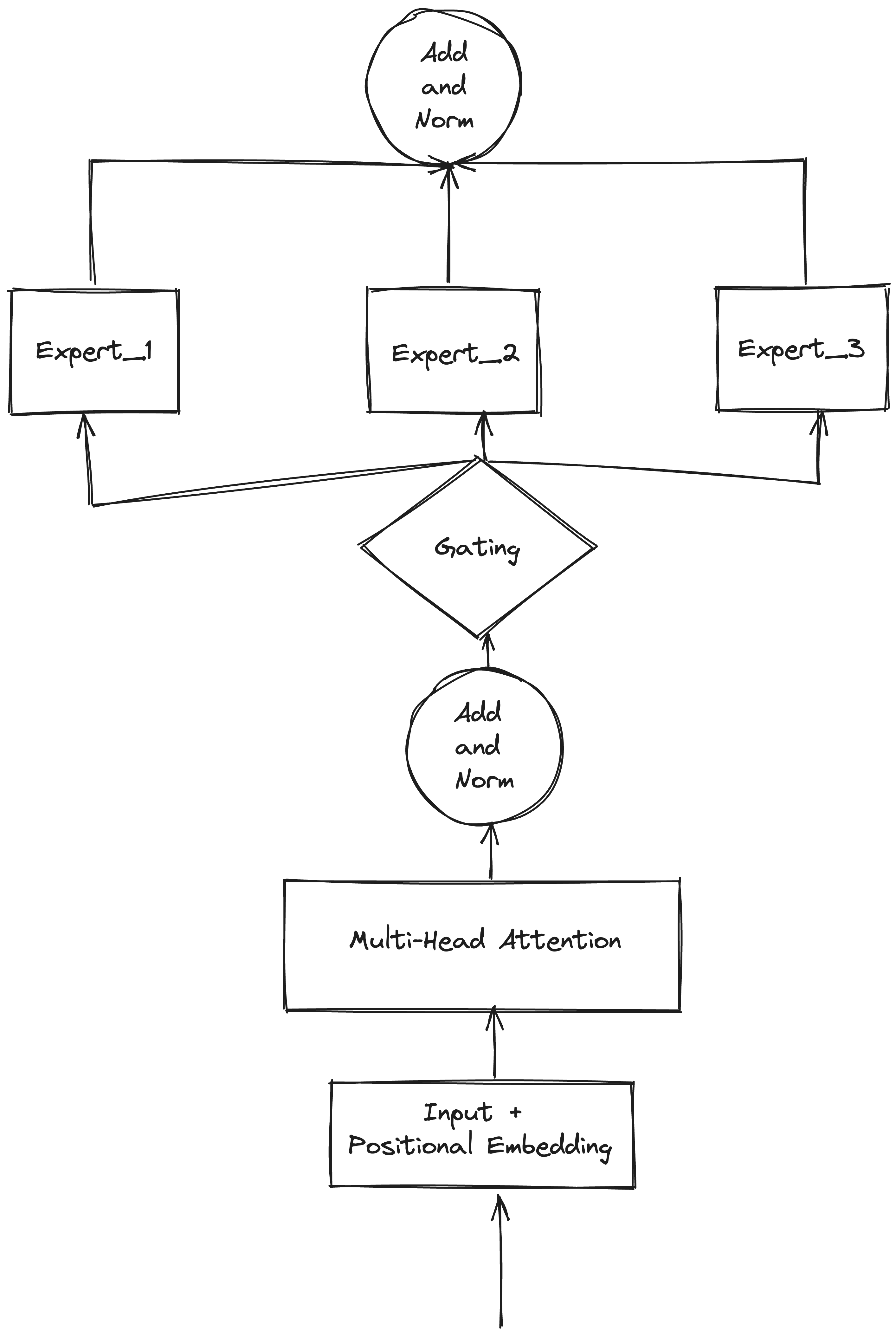
- MoE layers (position-wise) interweave with FFN layers in the Transformer encoder and decoder.
- Top-2 routing in the Gating Network selects the two most likely experts.
Lifelong-MoE
To tackle Lifelong Learning Google released Lifelong-MoE in May 2023. The model’s Lifelong learning strategy includes the following steps:
- Expand the number of Experts and the corresponding Gating dimensions.
- Freeze the old Expert and the corresponding Gating dimension, and only train the new Expert.
- Use the Output Regularization method to ensure that the new Expert inherits the knowledge learned in the past
Quiz Time!
Wrapping Up…
Think of MoE as a group of scientists working on a complex project. Each scientist has their own expertise and focuses on a specific task. There is also a lead scientist, who chooses which project to push and which to halt based on their features.
This allows the entire project to be completed more efficiently and effectively.
MoE is a relatively new technique in the field of LLMs, so the research is voluminious and growing each day. However, its potential benefits are significant, and it is expected to play a major role in the future development of LLMs.
References and Acknowledgement